WhichBenefit:
Multi-Class Classification of Customer Financial Transactions
Have you ever received a benefit package from an employer and felt that it was too complicated to keep track of your spending amounts? And don’t you find that the benefit reimbursement process is inefficient and wastes a lot of time?🕑
To address these increasingly common problems, the startup Benepass is combining employer benefits and stipends on a single payment card in order to simplify and modernize the benefits process. 💳 For example, if I am an employee at Company X, I now have a credit card that allows me to purchase all of my eligible benefits (e.g. internet bill, transit bill, health flex spending account…).
THE BUSINESS PROBLEM —
Benepass has an important pain point: When an employee from Company X goes to a store and purchases something, how can Benepass use the transaction data to assign it to a benefit category that the employee is eligible for?? Currently this assignment is done with a rule-based heuristic model which is only ~60% accurate and not generalizable.
This is where WhichBenefit comes in! WhichBenefit is a data product I developed in 4 weeks while consulting with Benepass which addresses this pain point while fulfilling the following company requests:
- As a deliverable, it automates and improves the classification process🤖
- It produces probability scores for each benefit class which gives a confidence in the prediction. (The company preferred a model that produces probability scores such that it could potentially help with future tasks such as fraud detection)🎯
- It can be integrated into their production workflow in the form of a production-ready Python package💻
THE DATA —
Benepass provided me with data that had a mixture of numerical, text, and categorical features (green), eligible benefit data which I used for post-processing (yellow), as well as multiple labels (blue).

The set of labels (possible benefits) consisted of 19 benefit classes that are meant to span all potential types of benefits. This ensures that new employers who work with Benepass can easily set up their benefit programs using this list of potential benefits. From a data science perspective, this also ensures that the model will need far less updating in the future, since it will not have to be retrained every time a new label appears in the dataset.
In general, I overcame 3 significant challenges with this dataset:
- There were only 3 usable features
- There were only 350 rows, so the dataset was very small
- The labels were highly imbalanced
Considering the size and type of data, I had to carefully think about how to select, preprocess, and engineer my features such that I could prepare them for use in a classification model.
PRE-PROCESSING AND FEATURE ENGINEERING—
In order to engineer my features, I treated each feature independently and tried to extract as much useful information from them as possible.
Cents: This numerical feature is the USD amount in cents for each transaction. Negative values indicate that the purchase was a credit purchase and positive values indicate a debit purchase, where the amount was then transferred to or from the Benepass credit card. I chose to scale the data to unit variance by dividing each value by the standard deviation, such that the positive and negative USD amounts stay positive and negative, respectively. (Hint: This scaling is also important since I use regularization during the modeling stage).
Merchant_category: This categorical feature is the VISA Merchant Category Classification (MCC) code which describes the type of merchant at the point of transaction. Of the hundreds of MCC codes, only 53 were found in this dataset and so I OneHot encoded them into a sparse matrix as shown here (where each merchant category now becomes its own column):

While this does add 53 columns to my feature list, these features span a large range of business types that offer benefits; and I expect these features to be generalizable such that new transactions fall within these categories.
In the rare event that a transaction enters the pipeline with a completely new merchant category, it can be flagged for manual inspection and potentially added as a feature for the next iteration of the model! 🔁
Merchant_name: This text feature is the name of the merchant as it appears on a VISA transaction record which is, funny enough, often times hard to understand even for the credit card owner. To clean this data, I chose to remove punctuation marks and numerical characters that were not directly part of the merchant name. I then turned this resulting string into a list of lowercase tokens to break down the merchant name into keywords.
🔧 Now comes the actual feature engineering! Using merchant name keywords and vectorizing (or OneHot encoding) them into columns is neither meaningful nor scalable. I also found that on a first pass through a ML classification model, the model had difficulty differentiating between health-related merchants such as pharmacies and doctor clinics. So instead I chose to create benefit-specific keywords from the training set such that companies with similar names tend to be classified into similar benefit categories.
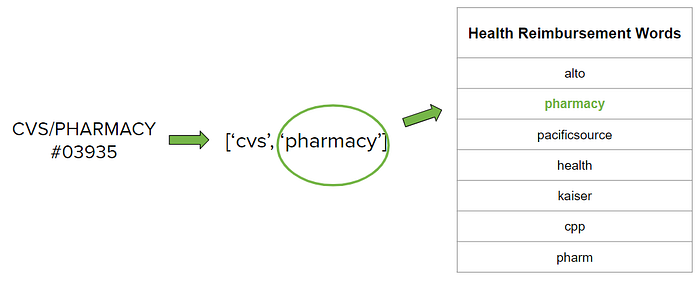
DATA AUGMENTATION —
In order to remedy both the small number of datapoints and the imbalanced classes I chose to oversample the less populated classes. I did this using a technique called SMOTE which was performed on the training set and resulted in a uniform distribution of labels. Essentially SMOTE makes copies of your data to increase the number of underrepresented classes. If the data is numerical, SMOTE can interpolate between the available data to generate new numerical features. By augmenting the data, my model can be trained on uniform data and tested on imbalanced data as seen below.

MODEL SELECTION AND TRAINING —
Because this was a multi-class classification problem which requires probabilities as output, I started by selecting a multinomial logistic regression model which is one of the simpler machine learning classifiers. I performed 5-fold cross-validation to select the most appropriate optimizer and model parameters which ended up being:
- L-BFGS Optimizer
- L2 Regularization (Ridge Regression) with C=1.0
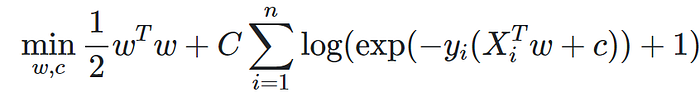
The L-BFGS optimizer is able to minimize this logistic ridge regression cost function in under 100 iterations as implemented in Scikit-learn and the resulting weights (w) and intercept (c) define our fitted machine learning model!
When compared to other classifiers such as random forest or gradient boosting, multinomial logistic regression proved to be faster and more scalable which is important since Benepass recently began scaling up their operations. 📈
Timing: Logistic Regression (100ms), Random Forest (160ms), Gradient Boosting (1600ms)
It also turns out that this model was able to classify just as well as the others, which made it my model of choice. During my cross-validation, I chose to optimize for the weighted-average F-1 metric for 2 reasons:
- The F-1 score, by balancing the precision and recall for classification, allows for a more robust classifier in which a perfect model would have a score of 1.0. There were also no obvious business use cases for preferring precision vs. recall since a misclassification could always be flagged for manual inspection in a timely manner.
- Because I am dealing with a multi-class classification problem, there are different ways to take the average of the F-1 score. To address the imbalance of the test data I focused on the weighted-average F-1 (WA-F1) metric such that the support of each class was represented proportionally.

Note that the WA-F1 score of 0.93 for my multinomial logistic regression model is scored after post-processing, which is described next!
POST-PROCESSING —
One of the useful pieces of data which is specific to this business problem (and dataset) is that each employee has a unique set of benefits that they are eligible for. For example, of the 19 total benefit types that Benepass has generated, a company usually only has a subset of these in their employee benefits package. I use this information to narrow down the probabilities of benefits for which an employee is eligible for, which helps improves the final F-1 score. Note that this information would be less useful as a feature for the machine learning model because the number and combination of eligible benefits varies greatly from company to company, and this approach would likely require a different machine learning model for each set of possibilities.

BUSINESS VALUE ADDED AND NEXT STEPS —
During this 4 week project, I successfully created a multi-class classification model which significantly increases the performance over the current approach and which generalizes to new companies and transactions. It does this by producing probability scores of each class, which can be more useful than a strict classification output because it allows for Benepass to be flexible with their future operations (let’s say they want to use probabilities or relative probabilities to aid in assessing fraudulent transactions).
I am also happy to say that the packaged code was implemented into Benepass’ live production pipeline, and is currently helping them classify new transactions in an automated fashion!!

For future work, I anticipate that the machine learning model would need to be periodically updated with larger and more varied training data as new card transactions enter the pipeline. I was also fortunate enough to have access to OpenAI’s Generative Pre-trained Transformer 3 (GPT-3) model in which I experimented with new ways of categorizing my transaction features. In the future, work can be done with this amazing NLP tool to help derive new features or augment the current features. Another possible route for model enhancement could be to bring in external dataset related to Benepass’ new phone app. Using more personalized app data could help to better predict which benefit category a transaction belongs to.
Finally, I want to thank the Insight team for putting me in contact with Benepass and for my consulting partners at Benepass who I learned a great deal from. Thank you for being a pleasure to work with! 😁





